
Organizations today generate enormous volumes of data — from website logs and customer transactions to sensor readings and social media activity. Storing, organizing, and making sense of all that information is one of the central challenges of modern business. A data lake is one of the most powerful tools available for doing exactly that.
At its core, a data lake is a centralized storage repository that holds large amounts of raw data in its native format until it is needed. Unlike traditional data systems that require data to be structured before it can be stored, a data lake accepts structured, semi-structured, and unstructured data all in one place. This flexibility makes it an attractive option for organizations dealing with diverse, high-volume data streams.
This guide explains what data lakes are, how they differ from data warehouses, why businesses adopt them, and what real-world scenarios they are best suited for. Whether you are a business decision-maker evaluating your analytics infrastructure or a curious reader exploring modern data concepts, this article covers the essentials clearly and practically.
What a Data Lake Is and How It Works
A data lake is a large-scale storage system designed to hold raw data in any format — structured tables, semi-structured files like JSON or XML, or fully unstructured content like images, videos, and documents. The defining characteristic is that data enters the lake without being transformed or filtered first. It is stored as-is, ready to be processed later when a specific need arises.
The Flow of Data Through a Lake
The typical lifecycle of data in a lake follows these stages:
- Ingestion — Data arrives from multiple sources: databases, APIs, application logs, IoT devices, social media platforms, or file exports.
- Storage — All incoming data is stored in its raw form, usually in a flat, object-based storage system on the cloud, such as Amazon S3, Azure Data Lake Storage, or Google Cloud Storage.
- Processing — When analysts or data scientists need to use the data, they apply a schema at query time — a practice known as schema-on-read — and process only what is relevant to their task.
- Consumption — The processed output feeds dashboards, machine learning models, business reports, or other downstream systems.
Data Formats a Lake Can Hold
Data lakes are designed to handle virtually any type of data:
- Structured data: relational tables, spreadsheets, SQL exports
- Semi-structured data: JSON, XML, CSV files, application log files
- Unstructured data: images, audio, video, PDFs, raw text documents
This breadth of support is what sets a data lake apart from older, more rigid storage systems that demand a fixed schema before any data can enter.
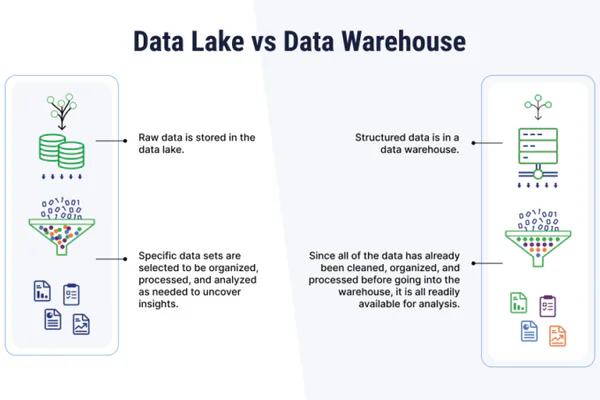
Data Lake vs. Data Warehouse
The most common point of confusion is the difference between a data lake and a data warehouse. Both store data for analytics purposes, but they serve different goals and follow very different design philosophies.
| Aspect | Data Lake | Data Warehouse |
|---|---|---|
| Data format | Raw, any format | Processed, structured |
| Schema approach | Schema-on-read | Schema-on-write |
| Storage cost | Lower (object storage) | Higher (optimized engines) |
| Flexibility | Very high | Moderate |
| Query performance | Variable | High for known patterns |
| Typical users | Data scientists, engineers | Business analysts, executives |
Choosing Between the Two
A data warehouse is built for predictable, repeated queries on clean, structured data. It excels when business analysts need consistent reporting — monthly revenue figures, customer churn rates, or inventory summaries. The data is curated, governed, and ready to query with speed and reliability.
A data lake is better suited when you do not yet know what questions you will ask, or when you need to store raw data from many diverse sources for later exploration. Data scientists working on machine learning models often need access to large amounts of raw historical data that has not been pre-processed or filtered in any way.
Many organizations today use both — a data lake for raw storage and experimentation, and a data warehouse for polished analytics and reporting. This combined approach is increasingly described as a data lakehouse architecture.
Why Organizations Use Data Lakes
Data lakes have grown significantly in adoption over the past decade, driven by the explosion of data volumes and the rise of machine learning and AI initiatives. Here are the primary reasons organizations choose to implement them.
Scalability Without Redesign
Cloud-based data lakes scale nearly infinitely. Organizations can add petabytes of data without reconfiguring their storage architecture. This is a major advantage over on-premises systems, where adding capacity often requires hardware procurement and extended downtime.
Lower Storage Costs
Object storage — the technology underlying most cloud data lakes — is significantly cheaper than the optimized columnar storage used in data warehouses. For organizations storing terabytes or petabytes of data that may not be queried frequently, this cost difference is substantial.
Flexibility for Diverse Data Types
Because data lakes impose no structure at the point of ingestion, they can accept data from virtually any source. A single lake might hold customer transaction records, server logs, product images, audio from call center recordings, and sensor data from factory equipment — all stored together and queryable on demand.
Enabling Machine Learning and AI
Machine learning models require large volumes of raw, historical data for training. Data lakes are ideal ML data sources because they preserve original data without transformation, giving data scientists full control over how they clean, label, and use it. Feature engineering and data preparation happen downstream, not at storage time.
Centralized Data Repository
Instead of data sitting in dozens of siloed systems — one per department or application — a data lake creates a single source of truth for the organization’s raw data assets. This simplifies governance, reduces duplication, and makes cross-functional analytics more feasible for large teams.
Common Data Lake Use Cases
Understanding where data lakes are actually deployed helps clarify the problems they solve and the scenarios where they deliver the most value.
Log and Event Analytics
Servers, applications, and network infrastructure generate continuous streams of log data. A data lake can collect all of this in real time, enabling later analysis of system performance, error patterns, or security incidents. Log data is typically semi-structured and grows very fast — exactly the kind of workload a data lake handles well.
IoT Data Collection
Internet of Things devices — from smart thermostats to industrial sensors — generate high-frequency, time-stamped readings. A data lake absorbs these streams without requiring each device to conform to a predefined schema. Engineers can later query specific time ranges, sensor types, or geographic zones to identify patterns or detect anomalies.
Customer Behavior Analysis
E-commerce platforms and digital services track every click, search, session, and purchase event. Storing this raw clickstream data in a lake allows analysts to reconstruct user journeys, test attribution models, and build recommendation engines without committing to a fixed analytical structure upfront.
AI Training Data
Training a machine learning model — whether for image recognition, fraud detection, or natural language processing — requires massive datasets. Data lakes store the raw text, images, audio, or transaction records that serve as training inputs. Data teams can iterate quickly, pulling different subsets and applying different transformations without needing to restructure the underlying storage layer.
Archiving Semi-Structured and Unstructured Data
Some organizations use data lakes as a long-term, cost-effective archive for data that does not fit neatly into relational tables — legacy file exports, regulatory records, contracts, or historical documents. The low cost of object storage makes this practical at petabyte scale.
Real-World Examples of Data Lakes
Looking at how different industries apply data lakes makes the concept concrete and easier to evaluate against your own organization’s needs.
Retail and E-Commerce
A large online retailer collects data from its website, mobile app, inventory systems, and logistics partners. Each source has a different format and update frequency. A data lake centralizes everything — product views, cart events, shipping statuses, return records — making it possible to run cross-channel analysis and train personalization models without restructuring source systems.
Healthcare
Hospitals and health systems generate data from electronic health records, medical imaging systems, wearable monitors, and laboratory equipment. Much of this data is unstructured or semi-structured. A healthcare organization might use a data lake to aggregate patient records, imaging files, and clinical notes, enabling researchers to run population health studies or build diagnostic models while keeping raw data intact for regulatory compliance.
Financial Services
Banks and insurance companies monitor transactions, claims, market feeds, and customer interactions continuously. A data lake allows financial institutions to store raw transaction data at scale, then apply analytics to detect fraud patterns, model credit risk, or identify compliance violations — all without pre-committing to which questions will be asked.
Manufacturing
Smart factories instrument their equipment with sensors that report temperature, vibration, output rate, and dozens of other signals. A manufacturer can route all sensor telemetry into a data lake and later run predictive maintenance models to identify which machines are likely to fail — reducing downtime and repair costs before a breakdown occurs.
Challenges and Best Practices
Data lakes offer significant advantages, but they also introduce real risks when not managed carefully. Understanding these challenges upfront prevents costly and time-consuming missteps.
The Data Swamp Problem
Without clear governance, a data lake becomes a data swamp — a massive collection of files that nobody can find, trust, or use effectively. Data arrives without documentation, schema changes go untracked, and teams lose confidence in the quality of what they have stored. This is the single most common failure mode for data lake projects, and it is entirely avoidable with the right practices in place.
Security and Access Control
Centralizing all organizational data in one place creates a high-value target for security threats. Without proper access controls, sensitive customer records, financial data, or proprietary research could be exposed to unauthorized users. Role-based access, encryption at rest and in transit, and audit logging are baseline requirements — not optional extras.
Best Practices for a Well-Managed Data Lake
- Implement a data catalog: Tag every dataset with metadata — source, owner, format, date, and purpose — so users can find and evaluate data quickly.
- Enforce data quality standards: Define what acceptable data looks like and validate incoming data before it enters the lake.
- Apply lifecycle management: Define retention policies and automatically archive or delete data that is no longer relevant or required by the business.
- Use a layered architecture: Organize data into raw, cleaned, and curated layers so teams can trust the data they use without reprocessing it from scratch each time.
- Monitor access and usage: Track who queries what, flag unusual access patterns, and review permissions on a regular schedule.
When a Data Lake Makes Sense
A data lake is not the right solution for every organization. Knowing when to use one — and when to choose a warehouse, a simpler database, or a hybrid approach — prevents over-engineering and wasted investment.
A data lake is a strong fit when:
- Data volumes are large and growing fast, from hundreds of gigabytes to petabytes
- Data comes from diverse sources with different formats and arrival rates
- The organization has active data science or machine learning workloads
- Analytical questions are exploratory or evolving rather than fixed and repeatable
- Cost-effective storage of raw or historical data is a priority
A data lake may not be necessary when:
- Your data is small-scale and fits comfortably in a relational database
- All analytics are based on well-defined, repeating business reports
- Your team lacks the technical maturity to govern and manage a lake effectively
- Speed and query performance for business reporting are the top priorities
For many mid-to-large organizations, the answer is a hybrid approach — sometimes called a data lakehouse — that combines the low-cost, flexible storage of a data lake with the query performance and governance structure of a data warehouse, giving teams the best of both architectures in a single, unified system.
Conclusion
Data lakes fill a real gap in the modern data infrastructure toolkit. They give organizations a cost-effective, flexible way to store and later analyze massive volumes of diverse data — without forcing rigid structure at the point of collection. When governed properly, they become a foundation for machine learning, exploratory analytics, and cross-functional data sharing that would be difficult or impossible with traditional storage systems alone.
The key is intentionality: know why you are building a data lake, who will use it, and how you will keep it organized and secure. With thoughtful governance and the right architecture in place, a data lake can become one of the most valuable assets in an organization’s technical infrastructure — a living repository that grows with the business and enables better decisions at every level.
{kind=link}